
Artificial Intelligence
The Hitchhiker's Guide to GPT3
~ 20 minute read
Giani Statie
Machine Learning Software Engineer
16 Feb 2022
GPT (or Generative Pre-Transformer) is a Natural Language Model, created by Open AI, capable of predicting which word comes next in a sentence, similar to Google’s autocomplete. What makes it stand out is the ease with which anyone can condition the Model to generate human-like text, by only showing it a few examples.
This is the main reason for which Elon Musk, the co-founder of OpenAI, was too afraid to make the AI open to the public. His main concern was that people would start using it to create realistic fake news [source]. However he soon understood that such technology will be inevitably available to the public, hence the latest version of GPT is currently available as an open beta [source].

how GPT-J (a smaller version of GPT3) generates new text starting from “Game of Thrones is …”
The curriculum of our journey consists in us going over a few of the Language Model landmarks from the past few years:
- 2015 - Attention - based on the paper Attention-based Models for Speech Recognition
- 2017 - Transformers - based on the paper Attention is All You Need
- 2018 - GPT - based on Improving language understanding by Generative Pre-Training
- 2019 - BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding
- 2020 - GPT3 - based on Language Models are Few-Shot Learners
in order to better understand how GPT was invented and how its components work.
Generations of work for today's progress
Most great magic tricks are built through generations of magicians who hone their skills behind the curtains.
The same thing can be said about the development of an AI algorithm. There are countless engineers, working full time on perfecting their models behind their desks.
Us, as mere spectators, can either see the unfolding of their trick and let our minds be blown or start questioning how it came to happen.
Starting from the basics
If we look up GPT and what makes it tick we’ll start seeing terms like transformers, attention and self-attention, but in order to properly understand how GPT works we need to take a few steps back.
What are LSTMs
Before GPT and transformers, LSTM (Long-Short Term Memory) cells were the best thing to use in applications where data had to be treated in an orderly manner (e.g. reading a text one word at a time, from left to right).
The way an LSTM cell works is that, for each word in the sentence, the cell will use an embedding (a vector of numbers) of the current word together with an embedding from the previous word (if any) to predict an output word.
To make things more clear, let’s consider a naive example of translating the English sentence “I like pizza” to it’s French counterpart “J'aime la pizza”.
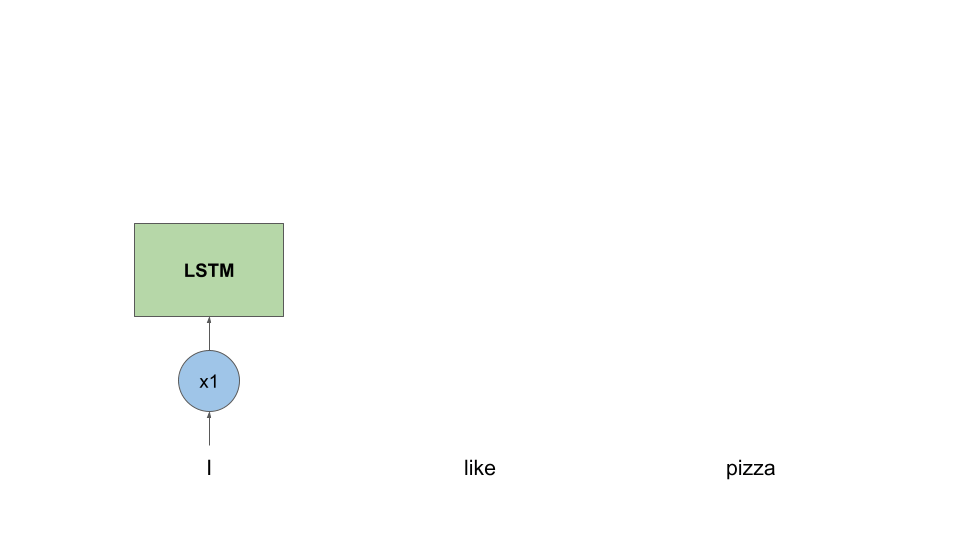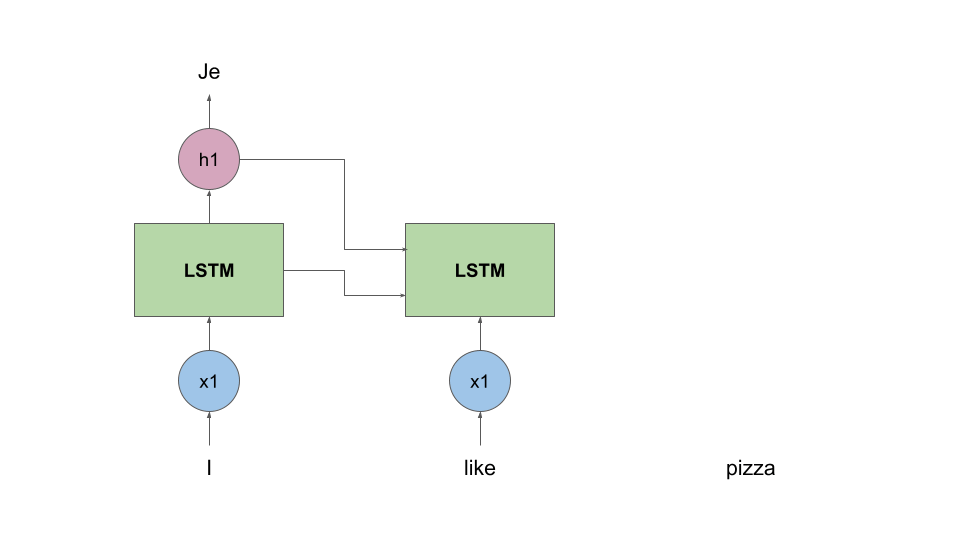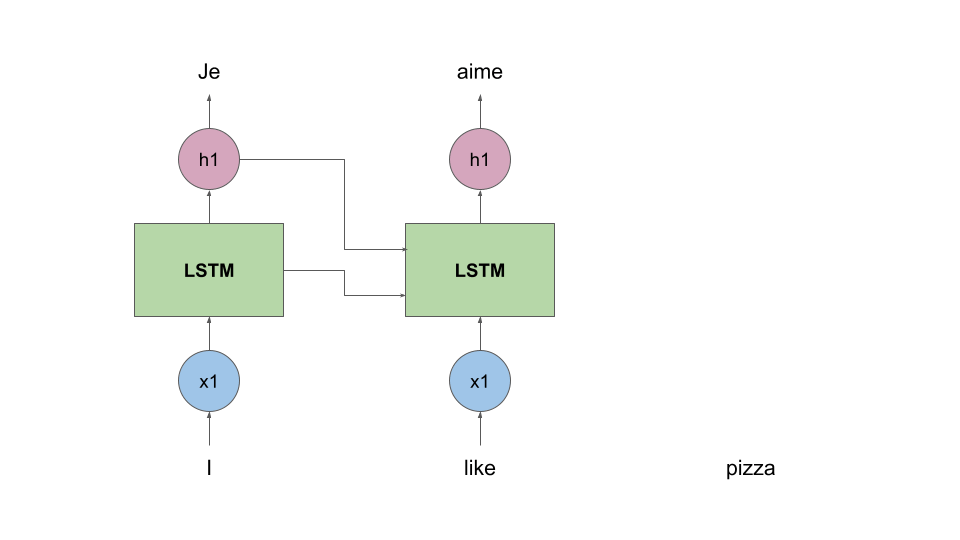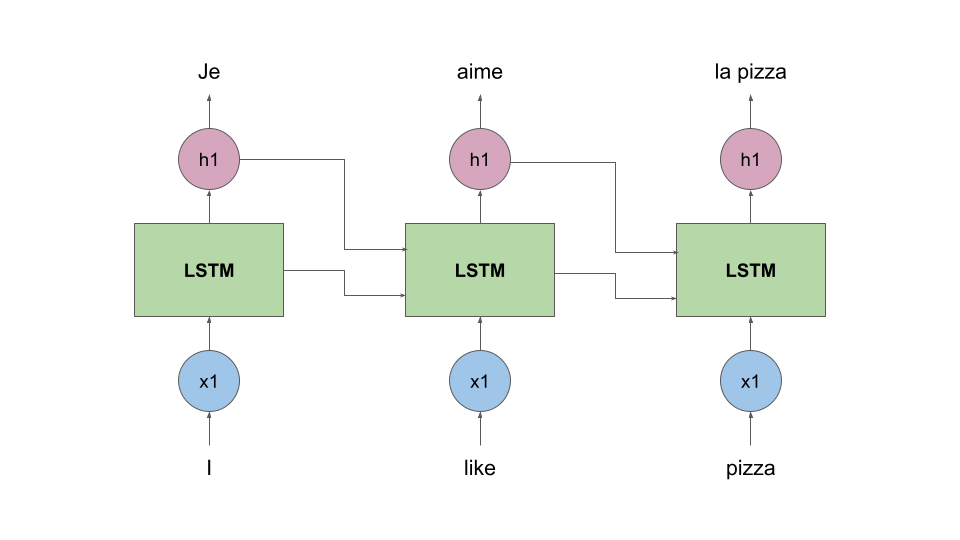
high-level view of how a LSTM block works
What we are going to do is:
- Break the sentence into words
- Create an embedding for our words (transform the text into a vector of numbers)
- Push the embeddings through the LSTM to predict the translation embedding
- Transform the translation embedding into a word
The LSTM is “trained” by producing word embeddings very similar to the true ones. Also, the same LSTM cell is used to predict the entire sentence.
This can be compared to us looking at a sentence word-by-word and trying to figure out what “like” should sound like in French, knowing that we already translated “Je”. You can find a more detailed overview of the way LSTMs work in this video.
As a side note, there are more efficient and robust ways of doing text translation, but these are the main ideas for training a Language Model.
What is attention
The main drawback of LSTMs is that they are overwhelmed when it comes to long temporal dependencies (long sentences) and inputs of varying lengths.
For instance, let’s consider a long sentence like “The boy who likes swimming, programming, hiking and playing games is named Marcus”. In order for the LSTM cell to link that “The boy” and “Marcus” are related, it will have to store information from the first word and keep it until the last. This will occupy the “memory” of the cell and it will constrain it from processing words from other timestamps.
Attention is a component that was invented with this limitation in mind. If placed on top of an LSTM cell, it allows it to pick which past embeddings it needs to predict the current word.
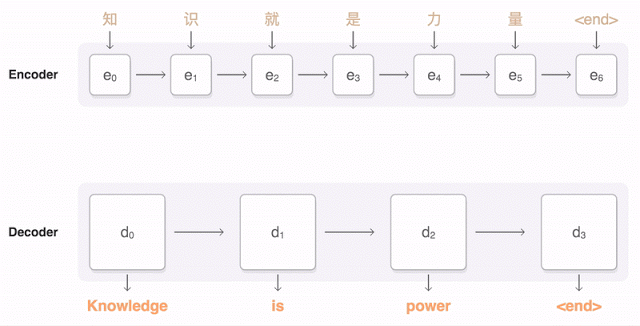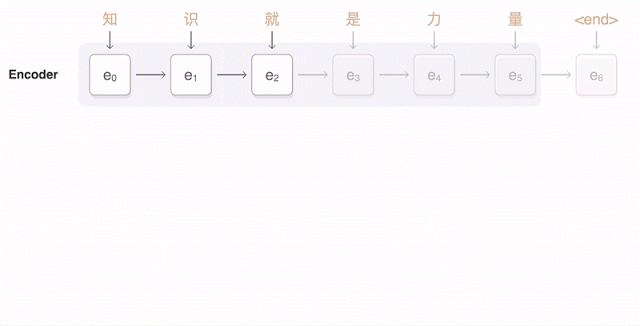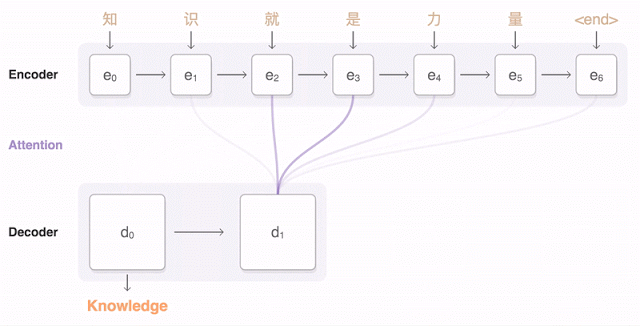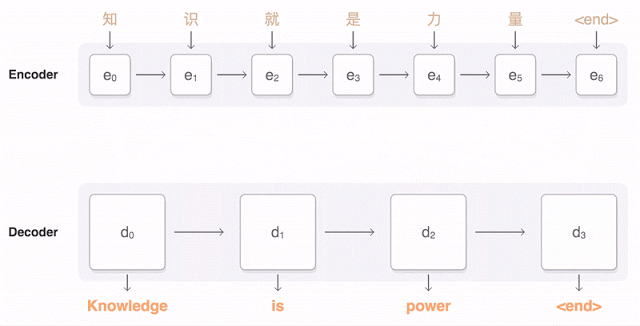
Attention-based encoder-decoder architecture
In the image from above we see how attention is used to take information from multiple prior words rather than relying on previous timestamp information.
What are transformers

Graphical representation of the transformer architecture
Another drawback of LSTMs is that they require multiple loops in order to iterate through all the words in a sentence. This, combined with the operations of applying activation functions over big tensors, make LSTM a pain to properly train and deploy.
Here is where transformers come to action. Transformers utilize attention together with skip-connections in order to process the sentences in a single shot.
Though the transformer architecture may look daunting (see image on right), we will go step-by-step and create a high-level overview of it.
First, the input sentence goes through a self-attention block (to identify key words in the original sentence), and produces the key and value tensors. The value tensors represent the embeddings of the input text and key tensors represent the strength of each embedding.
Secondly, the output text (if any) will be used to generate query tensors. Those query tensors are multiplied with the key tensors and their result is then scaled using a Softmax function. This resulting tensor is then multiplied with the value tensor in order to select only the data needed to generate the next output word.
The process is then repeated several times in order to produce an output sentence. You can check the references for a more detailed explanation.
It’s best if this time we exemplify by using an idiom such as “It’s raining cats and dogs”. Transformers will first go over the entire sentence and create a representation “in it’s head” (something like “It’s raining heavily”). Then it will use it’s decoder parameters to map the meaning of the sentence to the new language (in Romanian would be “Ploua cu galeata” or “It’s pouring from a bucket”). By doing so, we are able to extract meaning from entire sentences rather than individual words.
What makes GPT tick
GPT is built by stacking multiple transformer blocks and with each iteration (GPT, GPT2 and GPT3) it’s size gets bigger and bigger (more neurons and neuron connections). This allows it to store more statistical information for better predicting word relationships.
As seen in the image below, the components inside GPT are connected either directly or via residual connections.
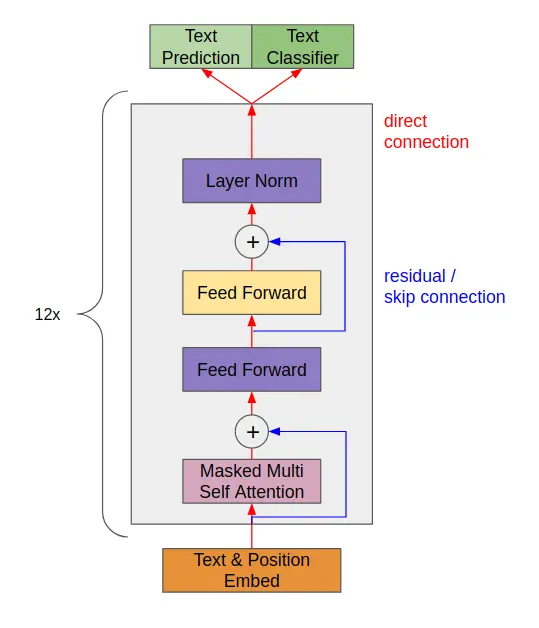
GPT-2 architecture leverages transformer’s strong points through the usage of direct and skip connections
The network is then trained in two steps:
- Pre-training via unsupervised learning by using unlabeled text. The network has to predict what is the following word in a sentence.
-
Fine-tuning on several subtasks:
- Natural language inference - whether two sentences contradict each other;
- Question answering - simple question answering (e.g. what is 2 plus 2);
- Semantic similarity - whether two sentences are similar/dissimilar;
- Sentiment analysis - whether a sentence has a positive or negative sentiment.
In addition to this, the model’s inputs are split into sub-components (sub-word tokenization) where words like “unbelievable” are split into “un”, “believe” and “able” in order to have a better representation for words which occur less often.
BERT: A new challenger appears
So far we’ve seen how language models look at phrases as a succession of words from left to right. However, there are also models which look at the entire sentence and can extract dependencies between all the words which compose it.
For instance, BERT (or Bidirectional Encoder Representations from Transformers) works by connecting attention embeddings in both directions. This allows the model to create contextual information between all the words in a sentence. In order to train BERT, the input is given as sentences with masked words (e.g. “We [mask] HEITS digital”) and its purpose is to predict what is the masked word. This forces the model to create contextual information by examining the context in which the word is put in.
An example of how GPT works compared to BERT is that GPT can be used for translation, while BERT can just fill in the gaps. For instance GPT can transform “I like pizza” to it’s French counterpart “J'aime la pizza”. However BERT can only fill in the gaps, by giving it “Je [mask] la pizza” it will output “aime” or another word with a high occurrence rate in similar sentences.
The image below offers us a high level view of how transformer cells are wired in the BERT model compared to GPT.
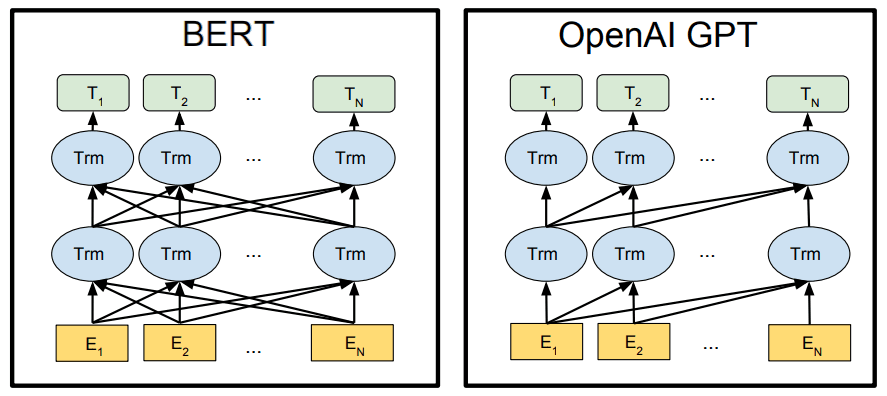
Differences in architectures between BERT and GPT
Following these changes, BERT was able to achieve state of the art results in text classification tasks in 2018. However, because of the way it was trained, BERT can only be used for extracting information from text and not so much for text translation or to create chat-bots.
How GPT-3 became the big bad wolf
Deep Language models are becoming bigger and bigger each year, with GPT-3’s 175 billion parameters being the record holder for the biggest architecture so far.
The reason? Usually when you increase the size of your network you give it the means to learn by heart the training set and stop generalizing. But with GPT-3 that moment is yet to come, which makes us curious to see how big it can get.
In the image below we see how the size of Deep Language Models increases over time, with the leader being Google’s Switch-C so far.
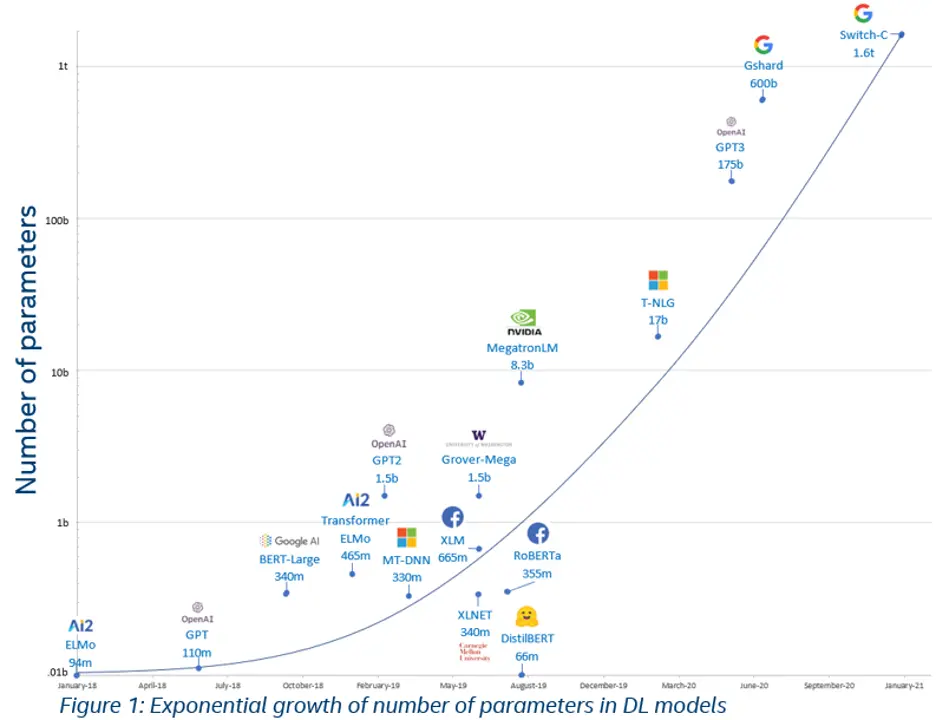
With great model architecture comes a great power bill
Along with its high dimensions, the cost of training GPT-3 is over 4.6 million dollars using a Tesla V100 cloud instance [source] and training times of up to 9 days.
Currently, one of the biggest concerns is that of how many resources have been invested into training such a model. But to our surprise, it doesn’t take a lot to repurpose GPT-3 for our own use case. With only a few (5 to 10) hand-picked examples, we are able to make GPT generate from DnD campaigns to even simple code snippets.
And even though the model is big and requires 40GB of video memory to do inference, there are ways to either split it on multiple GPUs, use RAM as storage or even use one of the free APIs from companies like Huggingface.
An AI which learns how to learn
Though not perfect, by taking advantage of pre-trained architectures similar to GPT-3, we are able to generate text which follows the structure of as few as 3 fine-tune examples. For instance, GPT-J was able to “calculate” sums, without it being specifically trained to do so (see image below).

GPT-J being able to generalize and answer given only a small batch of examples
Some researchers think that our next goal should be to make algorithms capable of “learning” how to learn [source].
Will we lose our jobs?
Consider you have a friend who speaks a language you don’t understand. In order to communicate with him, you bought a book in his language where you read that after “Ce mai faci?” you have to answer with “Bine. Tu cum esti?”. You still don’t understand what you’re saying, but your friend is happy and that makes you happy.
That’s practically what a language model does, it inferes what word/phrases statistically comes next. The difference is that the resulting mnemonic system may get the wrong words out from time to time. Overall the model is limited to the text it sees and the tasks that it is fine-tuned on and will not be able to generate new things, unless we specifically tell it to be more random.
Reusable neural networks are the future
Neural networks used in complex tasks such as text translation or autonomous driving are usually deep and require a lot of memory. And in order to tune the parameters properly we need to expose the network to diverse but relevant scenarios. This is because every time the network predicts a wrong word it’s penalized and it changes its weights such that next time it will predict something closer to the true word. Thus the amount and quality of the training/test data is vital in developing a good deep network.
In an ideal world we should only give networks 5-10 examples of high quality data and that would be enough for them to properly generalize (few-shot learning).
We can achieve something close to this by taking a backbone network which was trained on a generic task and fine-tune it on our specific task. This works because training a network to translate from English to Spanish when it already knows how to translate from English to Italian is usually faster than having it learn Spanish or translation from scratch.
The more knowledgeable the backbone network, the more tasks we can fine-tune our own network on and the less training data we will require.
Imagination is our limit
AI is developing at a rapid pace, so fast that it’s sometimes hard to keep up with it. However, we do not need to worry about fully grasping all domains of AI, but to specialize and add these powerful tools to our arsenal.
GPT-3 is a tool which can be used to either create chatbots for your website, translate the subtitles for your Korean series or generate Dungeons and Dragons campaigns for when you have a writer’s block. And even if we don’t understand how hard it is to train it or how parameters need to be tweaked for it to properly work, it’s good to know the basics, such that when we start learning about the next big thing, we’ll have a good backbone (network).
References
I. Prerequsites
Understanding LSTMs - Text
Prerequisites summary - Text, Video
Attention-Based Models (2015) - Paper, Explanation
Attention Is All You Need (2017) - Paper, Explanation, Implementation
I. Prerequsites
GPT1 - Paper, Explanation, Summary
BERT - Paper, Explanation, Summary
GPT3 - Paper, Explanation, Summary
Written by

Giani Statie
Machine Learning Software Engineer
Share this article on

