Infrastructure
Microservices approach in machine learning
~ 7 minute read
Alex Rus
Senior Full-Stack Software Engineer
10 Nov 2021
Microservices had a huge impact in software architecture, from well structured business logic & ease of deployment to better scalability & cost optimisation, there is a lot to learn and apply in other fields.
Microservices work best at large scale, so this approach will work best in the right context. Not all
applications
are equal, for some of them a microservices approach might be a bad idea.
For example, using a microservices implementation will have higher operational costs if the user-base is not
that
big, however, when it comes to scaling, you can scale only certain services of your application (the ones that
are
most used), while with a monolith approach, you have to scale up the whole thing to meet the same demands.
In our use-case we need to solve different NLP problems, so how can microservices help us and what are the benefits?
Approach
Our first milestone is to create small NLP models. Each model will focus on solving one NLP problem. Rather than having one big NLP model to solve all the problems in our use-case, multiple smaller models will do this task better, as the model will get trained to do one specific task (but this depends on your dataset).
Smaller models will have a better execution time, and combining this with the fact that in our case we don't need to send the text through all the models will further increase the system's throughput.
Since we won't use all the models every time, in case one of them is used more, scaling will be simple, as we can scale that model alone, not the whole system, but we will talk more about scaling and optimizations in the next section.
What happens if in the future we need to add more models? Just add one new service to handle the new features and make small adjustments to your pipeline and you're set.
The next one will have to do with continuity, from time to time you need to improve and retrain your models, each time we want to do that, you can train each model individually, in a fraction of the time it would normally take to retrain the whole thing. You can have small, granular increments in your application.
Cost optimization
So far we talked about sectioning the monolith and the advantages we gain, but there's more we can do to
optimize
and improve the system's throughput.
Like mentioned above each service can run in it's own container and in case one model is more used than others,
we
can scale that one up to have more instances.
Also, I've mentioned that the input will not be passed through all the models, and this depends on the input
text.
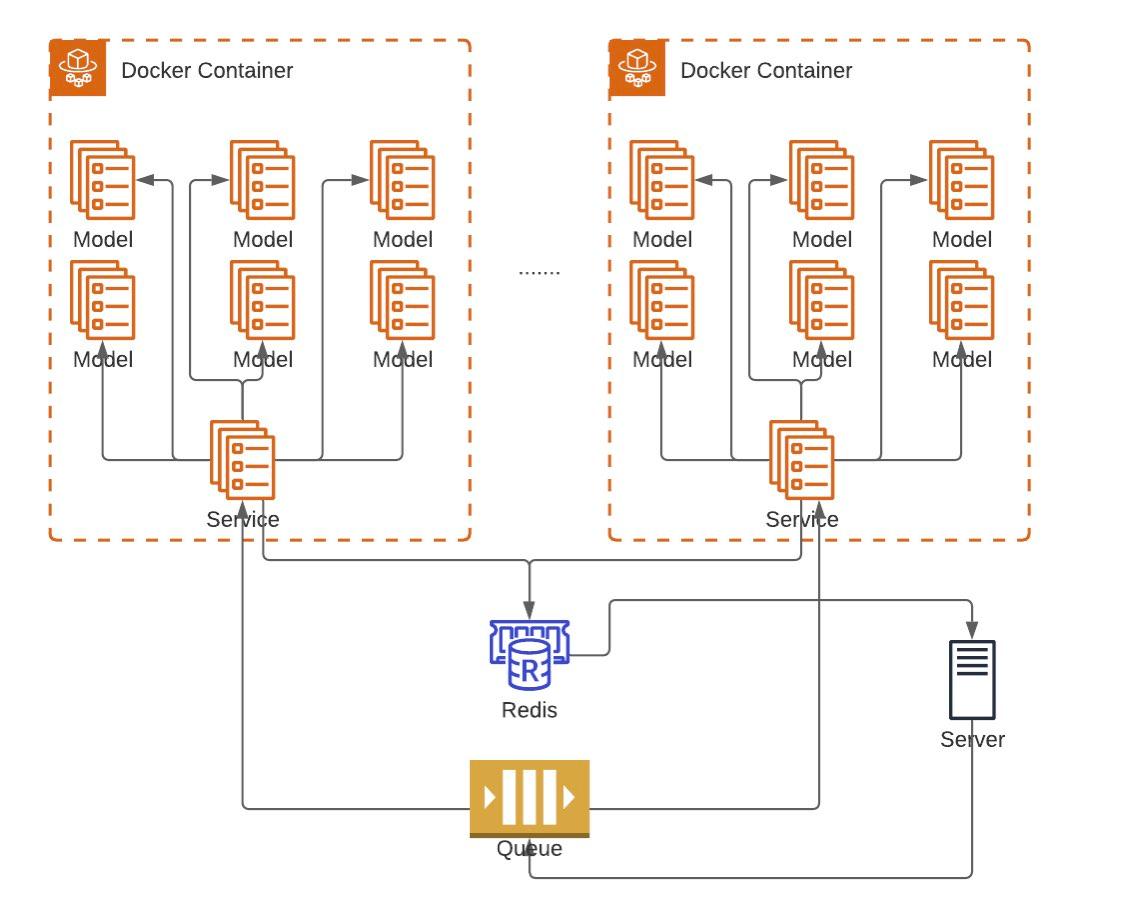
Combining the above two facts means that we'll have containers just sitting around from time to time, hence we enter the commasation phase, by combining multiple, or all the models in a single container.
Each container will work as its own entity, having a worker that receives the input, and delegates work to each required model, combining the result in the end and saving that result in a DB.
The below diagram illustrates how all components fit together and how scaling affects the infrastructure, like I previously mentioned, in case one model is used a lot we wanted to scale up that model, well, now we'll have to scale up the whole container, but this brings us another advantage: The fact one model has higher usage now, does not guarantee us that this trend will continue, but since we scaled the whole container, we are prepared in case there is demand for another model, preventing us from unnecessary scaling up and down of different models. When the whole system goes down in use, that's when we want to scale down our containers.
Conclusion
Besides the fact that you have better control on how each individual piece is working now, there is also the benefit that you can have better control of your infrastructure with the new approach. I'll have to say that the new improvements are also somehow dependent on your specific needs, only by analysing the existing product and how it operates can you extract the best result. In our case, the old implementation was not so good at parallelizing tasks, this means we had to have a lot of instances running, the new implementation started with removing these limitations from the beginning. Another important improvement we had in mind is the ease of adding new features and improving existing ones in the future.
Written by

Alex Rus
Senior Full-Stack Software Engineer
Share this article on
DISCOVER
Our Work